
Андрей Акопянц
В некотором смысле эта статья продолжает линию,
начатую в «КТ» #275 («Автоматизация хаоса»). Но не по тематике
(корпоративная информатизация), а как попытка рефлексии некоторого
пласта знаний, лежащего между философией и методологией разработки
систем, с одной стороны, и технической документацией на конкретные
продукты, с другой.
Это знания о том, что, собственно, происходит при разработке реальных систем, какие существуют типичные проблемы и подходы к их решениям. Это то, о чем говорят разработчики за кружкой чая или бутылкой водки, но что практически не встречается в виде печатного слова, так как тем, кто реально разрабатывает системы, как правило, некогда писать, а те, кто может и хочет писать, — чаще всего не владеют материалом. История вопроса — от 4GL до RAD
Еще десять лет назад все знали, что разработка клиент-серверных многопользовательских систем — это сложно. Разработка велась в основном на языках четвертого поколения, входящих в комплект соответствующих СУБД. За это брали много денег, и этим занимались в основном серьезные профессионалы. Нишу настольных приложений оккупировали умельцы, орудующие «народными» СУБД типа Clipper, FoxPro и Paradox, и слои практически не пересекались.
Но в начале 90-х радикально подешевели средства организации локальных сетей с разделяемыми файлами (файл-серверов), и появились «сетевые» версии настольных СУБД, позволяющие как-то обеспечить многопользовательскую работу. Они заняли промежуточную ценовую и квалификационную нишу между чисто настольными и клиент-серверными системами (ближе к настольным, естественно). Клиент-серверные разработки в нашей бедной (финансово) стране оказались вытеснены в область критически важных high-end-решений типа резервирования авиабилетов, учета на очень больших предприятиях, в крупных банках и др.
Но неумолимая поступь прогресса привела к тому, что в последние 3-4 года на рынке уверенно возобладали реляционные СУБД (сейчас уже многие не знают, что бывают и другие), и произошло сближение функциональности ряда лидирующих систем (Oracle, Informix, Sybase, DB2, Interbase, Progress). Цены на эти системы также заметно снизились (в разы), и клиент-серверная архитектура снова стала модной. Как всегда, важную роль в этом сыграла Microsoft, выпустив по демпинговым ценам «народный сервер» MS SQL, пользоваться которым поначалу было практически невозможно, но конкуренты вынуждены были снижать цены.
Это породило новые поколения инструментальных средств разработки, ориентированных на не слишком квалифицированного пользователя и стирающих различия в разработке настольных и клиент-серверных систем. Они имели графический пользовательский интерфейс (GUI) и получили собирательное название RAD (rapid application development) — новое модное слово, пришедшее на смену языкам 4-го поколения.
Их триумфу способствовал массовый переход на MS Windows, поменявший стандарты пользовательского интерфейса. Системы, не сумевшие быстро к ним приспособиться, либо вымерли (например любимая мною DataEase), либо перешли под Windows, но были дисквалифицированы общественным мнением за несоблюдение новых интерфейсных стандартов (Oracle Forms).
Профессия программиста становилась массовой, и новые системы стали массовым продуктом с соответствующими методами производства и маркетинга. «Клиент-сервер — это просто!», «ODBC за 21 день!», «Delphi для чайников» — зазывают рекламные проспекты и заголовки книжек. Каждые полгода выходят новые релизы, обещающие еще больше упростить и ускорить процесс разработки, хотя, казалось бы, уже некуда: совершенство (по заявлениям производителя) было достигнуто уже в предыдущем релизе.
Примеры, прилагаемые к дистрибутивам, демонстрируют, как легким движением руки создаются почти (!) настоящие приложения. Многослойные библиотеки визуальных компонентов заботливо скрывают от разработчика «излишние» подробности. У неискушенного зрителя может создаться впечатление, что все проблемы уже решены — бери и программируй.
Но не тут-то было. Сложности, носящие принципиальный характер, никуда не делись — их просто искусно замаскировали, точнее, протоптали и заасфальтировали некоторое количество обходных дорожек и обсадили их красивыми формочками, Help’ами и Wizard’ами. При этом в любой реальной разработке добраться по этим дорожкам до цели почти никогда не удается. Приходится выходить на обочину или вообще на бездорожье, и тут-то и выясняется истинная цена всей этой красоты.
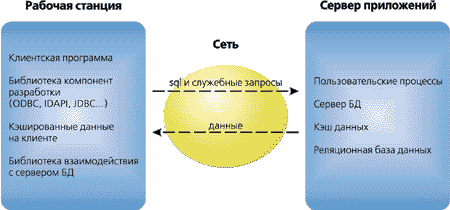
На самом деле, построить макет системы стало сейчас очень просто, а вот получить реальное промышленное приложение, обслуживающее многих пользователей при большой нагрузке, — столь же сложно, как и десять лет назад, и, может быть, даже еще сложнее за счет того, что выходя за пределы функциональности штатных средств, приходится обеспечивать высокие стандарты и единообразие интерфейса. Как устроены клиент-серверные приложения и зачем они нужны Базовая схема взаимодействия клиента и сервера в СУБД-ориентированных приложениях известна, но имеет смысл ее еще раз привести, так как именно из этой простой схемы следуют все реально имеющиеся сложности.
Происходящие при этом взаимодействия в основном выглядят так:
- клиент запрашивает у сервера данные, тот ему их возвращает;
- клиент велит серверу изменить данные, тот выполняет операцию, если может.
Кроме того, на сервере может выполняться часть содержательной обработки данных (так называемые хранимые процедуры) и поддержка логического соответствия данных (триггеры и ограничения целостности).
Принципиальными являются еще два понятия — транзакция и блокировка.
Транзакция — это последовательность запросов на изменение (и чтение, конечно) данных, обладающая таким свойством, что либо вся эта последовательность выполняется, либо от нее не остается (по возможности) никаких следов. Для обеспечения транзакции используются обычно операторы — транзакционные скобки Начать транзакцию, Завершить транзакцию или Откатить транзакцию, входящие в систему команд сервера и язык разработки хранимых процедур.
Блокировка позволяет отметить некоторый элемент данных таким образом, чтобы, пока его не «отпустили», никакой другой пользователь не мог его модифицировать.
Есть несколько причин, определяющих преимущества клиент-серверной архитектуры перед файл-серверной:
— уменьшение сетевого трафика за счет того, что выборка данных производится на сервере, и они не «прокачиваются» по сети;
— увеличение производительности за счет того, что сам сервер может эффективно кэшировать данные (в отличие от клиента, который никогда не может быть уверен в том, что его данные «первой свежести»);
— перенос части функциональности на сервер с уменьшением трафика и увеличением производительности;
-масштабируемость — при возрастании нагрузки достаточно заменить лишь сервер, а не все станции и сетевые платы;
— и наконец, самое главное, это наличие транзакций, без которых практически невозможно обеспечить логическую непротиворечивость данных.
Но за все приходится платить. Масса проблем возникает из-за того, что данные дублируются и на клиенте, и на сервере, причем сервер не знает, что известно клиенту, а клиент не знает, что поменялось на сервере. Держать слишком много данных на клиенте — плохо, так как они часто будут «портиться», и их придется пересчитывать, да и клиента перегружать не хочется.
Держать слишком мало — тоже плохо, чаще надо обращаться к серверу. А сервер устроен так, что ему наплевать, одну запись выдать или десять, — основное время все равно уходит на то, чтобы понять, что от него хотят.
Перекачивать все данные по запросу — плохо, так как часто нужны не все, а совсем немного (например, первые десять — сколько на экране помещается). По частям перекачивать с сервера результаты запроса — хорошо, но логически сложно, и возникает проблема с хранением на сервере состояния недообработанного запроса.
Блокировать все данные, которые я собираюсь менять, — хорошо, так как никто мне не помешает, но плохо, так как я могу помешать другим.
Транзакции, закрывающие от других пользователей «сырые», недоизмененные версии записей, также создают массу логических проблем. В общем, при переводе приложения на клиент-серверную архитектуру нетрудно получить эффект, обратный желаемому, — в виде заметного увеличения сетевого трафика и недопустимого замедления работы приложения. Дальше мы рассмотрим несколько типичных причин, которые могут привести к такому результату.
Три иллюзии
Беглое знакомство практически с любой современной средой разработки клиент-серверных приложений может создать несколько опасных иллюзий. Иллюзия подобия настольным СУБД
Все системы, выросшие из
средств разработки настольных СУБД, пытаются предоставить
разработчикам «родные» метафоры настольных СУБД: таблицы, индексы,
поиск и позиционирование в индексе, и т. д. Так и тянет реализовать
задачу в виде таблички, где можно искать по первым буквам
названия…
Но нельзя забывать, что так называемые таблицы и
индексы все равно реализуются SQL-вызовами, и на запрос открытия
таблицы скорее всего выполнится что-то типа Select * from table
ordered by Index. А на такой запрос разные серверы реагируют
по-разному.
Несколько лет назад мне рассказали трагическую
историю: в «ТверьУниверсалБанке», бывшем тогда в полном расцвете
сил, решили осовременить систему межбанковских расчетов, по которым
«ТверьУниверсалБанк» был лидирующим банком страны. Прежняя система
была написана на Clipper, работала на Nowell’овской сетке и
задыхалась от огромного объема проводок, вводимых несколькими
десятками операторов.
За шестизначную сумму был приобретен
крутой сервер Sun и комплект средств разработки
Oracle. Задача была
довольно быстро переписана и запущена… После чего выяснилось, что
она не тянет больше пяти пользователей, да и тех с трудом.
Длительные разбирательства показали, что новая программа,
воспроизводящая старую, «клипперную» идеологию, начинала с того, что
открывала все нужные ей таблицы с помощью приведенных выше
запросов.
Честный Oracle в свободное от обслуживания запросов
время скачивал все эти громадные таблицы в память для каждого
оператора отдельно (так называемая упреждающая буферизация). Чем
благополучно забивал всю память. После любого изменения,
произведенного оператором, он начинал «освежать» эти буферы. На что
у него уходил весь процессорный ресурс. А дисковая подсистема
трудолюбиво занималась подкачкой страниц виртуальной памяти, также
сажая при этом процессор.
За этой проблемой полезли другие. В
общем, в течение года систему запустить так и не удалось, а потом
банк помер. Когда я поведал эту историю одному знакомому
квалифицированному ораклисту, он чрезвычайно возбудился и начал
рассказывать, что, оказывается, нужно было просто подкрутить Oracle
некоторые настройки, правда, не описанные в основной
документации…
Еще одна типичная ошибка — попытка
организовывать обработку данных на клиенте. Можно легко понять
человека, не желающего учить довольно-таки корявые языки написания
серверных процедур и отлаживать эти процедуры в среде, зачастую
лишенной интерактивного отладчика. Но тогда надо быть готовым к
тому, что просмотр таблицы на клиенте будет работать примерно вдвое
— втрое дольше, чем в старом файл-серверном приложении, и во столько
же раз увеличит сетевой трафик.
У иллюзии подобия настольным
СУБД есть и другие неприятные следствия, которые мы рассмотрим в
разделе, посвященном организации пользовательского
интерфейса.
Иллюзия эффективной исполнимости SQL
SQL —
достаточно выразительный язык, и на нем можно сформулировать
подавляющее большинство запросов к данным, встречающихся в реальной
жизни. Но далеко не всем, что выразимо в
SQL, можно пользоваться на
практике.
Дело в том, что перед исполнением запрос должен
быть переведен в некоторую последовательность действий с таблицами и
индексами базы данных. Причем способов это сделать, как правило,
существует много, и из них нужно выбрать лучший. Этой задачей
занимается важнейший компонент любого SQL-сервера — оптимизатор
запросов.
В большинстве случаев оптимизатор удовлетворительно
справляется со своей задачей. Но на сложных запросах с большими
таблицами (соединение многих таблиц, вложенные запросы, группировки,
суммирования и др.) у него иногда «едет крыша», и запросы начинают
исполняться часами, «отъедая» под временные файлы все свободное
дисковое пространство. Причем, к сожалению, часто невозможно
сказать, почему это происходит и как изменить запрос, чтобы он
исполнялся за разумное время.
Развитые серверы содержат
средства борьбы с такими ситуациями в виде так называемых планов
исполнения: у сервера можно спросить, как именно он собирается
исполнять запрос, и подсказать ему, как это нужно делать.
Но
и этих возможностей не всегда хватает, поэтому нужно быть готовым к
тому, чтобы переписать ряд запросов в виде серверных процедур или
делить их на части и потом собирать результаты уже на
клиенте.
Иллюзия идентичности разных серверов
Почти
все современные средства разработки позволяют работать с разными
серверами баз данных. В значительной степени этому способствовало
сближение функциональных возможностей серверов баз данных и
появление стандартных программных интерфейсов для работы с ними
(ODBC, IDAPI, JDBC).
Таким образом, создается иллюзия, что
система, разработанная для одного сервера БД, может быть легко
перенесена на другой или, более того, можно сделать систему, которая
будет работать с различными типами серверов.
На самом деле
при внешнем сходстве различия между разными серверами баз данных
остаются достаточно глубокими, и они критичны для создания реальных
промышленных приложений.
А- У разных серверов разный
синтаксис и функциональные возможности языков разработки хранимых
процедур и триггеров.
Б- Поскольку разные серверы пользуются
разными алгоритмами оптимизации, то запросы, хорошо работающие на
одной системе, могут оказаться неэффективными на другой. А арсенал
способов управления эффективностью у них совершенно
разный.
В- Местами не совпадает даже синтаксис SQL — в части,
например, внешних соединений таблиц (outer
join).
Г-
Поскольку разные серверы пользуются разными принципами блокировок и
организации транзакций, то для эффективной многопользовательской
работы нужны разные способы организации программы. Дальше мы об этом
поговорим подробнее.
И наконец, каждый сервер имеет свои
собственные, уникальные и, как правило, очень полезные в конкретных
приложениях особенности, которыми грех не
воспользоваться…
На самом деле систему, работающую на всех
типах серверов, сделать можно, возложив всю функциональность на
клиентскую часть программы и используя только простейшие запросы для
доступа и модификации данных. Но она везде будет работать
недопустимо плохо.
Организация пользовательского интерфейса
Пользовательский интерфейс хорошей настольной
системы почти всегда выглядел следующим образом: очень длинный
список записей, представленный в табличном виде
(grid, datasheet), в
котором имеются поля из некоторой «основной» таблицы базы данных и
таблиц, с ней связанных (например, список складских проводок, в
которых видны названия товаров и получателей, хранящихся в отдельных
таблицах). Таблица некоторым образом отсортирована (по
дате/покупателю/товару). Мы стоим на некоторой позиции в этой
таблице.
Этот список можно листать вверх-вниз и искать
нужное, причем для названий поиск осуществляется путем набора
начальных символов и позиционирования в списке по ходу набора.
Результатом поиска является перемещение на нужную запись
(записи).
Запись (при наличии соответствующих прав) можно
редактировать как в таблице, так и перейдя в карточку текущей
записи.
Иногда возникает потребность отфильтровать нужные
записи. Минимумом тут является фиксированная форма задания условия
отбора, максимумом — возможность задания произвольного фильтра в
стиле QBF (Query by form — условия вводятся прямо в карточке записи)
или в виде «набора» условия в табличном виде из имен полей и
ограничений на них.
Так вот, буквально все описанные выше
элементы пользовательского интерфейса создают проблему при работе в
клиент-серверной архитектуре.
Начнем с того, что работа с
полным списком записей всегда создает некоторые логические проблемы,
в простых случаях незаметные, но иногда приводящие к тяжелым
последствиям. Для того чтобы понимать, как это в реальности будет
работать, нужно знать тонкие детали логики взаимодействия клиента и
сервера, иначе легко можно получить непредсказуемые задержки и
катастрофическое увеличение сетевого трафика.
Правильной
идеей является ограничение множества доступных записей некоторым
условием, чтобы их количество не превышало нескольких сотен. Но
тогда возникает проблема разработки такого интерфейса, в котором
пользователь
— понимает, что видит неполный список (Где
запись, которая — я точно знаю — была? Караул! База испортилась, в
программе вирус и проблема 2000 года!);
— видит, каким именно
условием ограничен текущий список;
— понимает, как изменить
это условие, и имеет возможность сделать это легко.
Мне не
известны стандартные метафоры для такого интерфейса. Похоже, что в
каждой задаче это нужно делать по-своему, выбирая «естественные»
способы деления полного списка на части, не заставляющие часто
менять условия и делать выборки, идущие «поперек» этого деления. В
нашем складском примере это могли бы быть календарные месяцы или
недели.
Следующей проблемой, тесно связанной с предыдущей,
является позиция. Дело в том, что SQL-сервер никакой «позиции» не
знает. Таким образом, для того чтобы позиционироваться в списке
записей, нам нужно тупо пролистать его до нужного места. Существует
альтернатива: дать серверу такой запрос, который выберет
«окрестность» искомой записи. Но тогда немедленно возникнут проблемы
при попытке выйти из этой окрестности вверх или вниз. Это факт может
быть несколько замаскирован, но понимать его нужно.
Здесь
нужно сказать следующее: практически во всех системах разработки
этот самый «список» может базироваться как на таблице базы данных,
так и на SQL-запросе. Несмотря на внешнее сходство, эти два варианта
сильно различаются по той функциональности, которую для них
обеспечивает инструментарий разработки, и по своему
поведению.
В случае работы с таблицей система, как правило,
всеми силами старается имитировать стиль работы, характерный для
настольных СУБД. Предоставляются понятия индекса, возможность искать
по ключу и др. При работе с таблицей, как правило, обеспечивается
удовлетворительная работа и с неограниченной выборкой (с точностью
до поведения сервера), и с позиционированием (см. дальше). Операции
редактирования данных имеют очевидную семантику. Переходы в начало/в
конец/на выбранную позицию списка происходят достаточно
быстро.
И всем этот вариант хорош, кроме одного: для
«подтягивания» полей из других таблиц приходится пользоваться
механизмом вычислимых полей и поштучно доставать их из базы. А это
создает большой поток мелких запросов к серверу, что, как мы уже
обсуждали, сажает как сервер, так и сеть. Визуально это проявляется
в том, что перерисовка экрана при скроллировании вверх-вниз
становится очень медленной, а время от времени просто
затыкается.
При работе с SQL-запросом по нескольким таблицам
(joined query) все меняется. Первый экран записей выдается, как
правило, достаточно быстро, и скроллирование выглядит гораздо
веселее, но… Попытка перейти в конец списка или вывести счетчик
числа записей может занять минуты. Если же вы попросили сортировку,
суммирование или группировку, минуты может занять и появление
первого экрана.
А для позиционирования на требуемую запись
часто не предоставляется даже программного интерфейса — нужно писать
самому (последовательным просмотром, естественно). Но самые
интересные вещи возникают при попытке обеспечить корректное
редактирование данных, полученных путем запроса.
Дело в том,
что редактирование «составной» записи — дело логически сложное.
Рассмотрим, например, нашу складскую проводку. Предположим, что мы
выдали ее представление, в котором есть дата, количество, цена,
название и адрес фирмы и название товара. Если мы исправим цену, то
более или менее понятно, что делать — править цену в исходной
проводке; если мы исправили адрес фирмы, тоже понятно — фирма
переехала. А вот если мы исправили название товара? Что это — товар
переименовали, или мы не тот товар вбили и теперь исправляем? А если
товара с таким названием нет — ошибка это или его нужно
добавить?
В разных системах разработки отношение к этой
проблеме разное. В Delphi вопрос решен радикально: она честно
считает, что результат запроса по нескольким таблицам вообще не
редактируем. В Delphi 1.0 эта проблема не решалась никак, а в версии
2.0 и выше появилась возможность самим описать, что мы понимаем под
редактированием такой записи, — механизм отложенных изменений.
Концептуально это правильно, только сложно очень… Я, достаточно
хорошо зная Delphi, провозился часа три, чтобы заставить этот
механизм работать. Правда, благодаря высокой инструментальности
Delphi, можно, решив эту проблему для некоего случая один раз,
оформить результат таким образом, чтобы в дальнейшем проблема
решалась одним движением руки. Не понятно, почему это не сделали
разработчики, наверное, не успели — торопились выпустить очередной
релиз.
Еще веселее с Access. Он, как все «мелкомягкие»
продукты, считает себя самым умным и разрешает редактировать
результат запроса без ограничений! Правда, что при этом творит!
Например, в приведенном выше примере он без малейших сомнений и
колебаний изменит название товара в таблице товаров. Если добавить
запись и ошибиться в названии фирмы на один символ, он также
уверенно добавит запись в таблицу фирм. Как он разбирается, что
нужно удалять в этом случае, для меня загадка… Можно, конечно,
запретить редактирование, но вот можно ли Access заставить вести
себя полностью корректно даже в частном случае, я
сомневаюсь.
На самом деле есть еще такая вещь, как View, —
это тот же запрос, но подготовленный средствами SQL-сервера. Из
клиентских программ с ним можно работать почти как с таблицей, но
редактировать, естественно, нельзя… Я не понимаю, почему эту
проблему не решили кардинально производители SQL-серверов и не
разрешили редактировать View путем обкладывания его триггерами на
добавление, удаление и модификацию, ведь логика редактирования View
является существенной частью бизнес-логики, которую стараются
все-таки держать на сервере.
С запросами связана еще одна
проблема — логика обновления данных в запросе после изменения
информации в «подлежащих» таблицах. Тут все, как правило, очень
непросто. Гарантию актуальности может дать только периодическая
перестройка запроса, но это достаточно тяжелая операция (опять же
потом нужно вернуться на текущую запись). А попытки системы решить
эту проблему самостоятельно приводят к возникновению непонятных
задержек в работе, причинами и временем появления которых управлять
почти невозможно.
В общем, при переносе некоторой системы с
файл-серверной архитектуры на клиент-серверную автор с коллегами так
и не сумели корректно решить все проблемы, и пришлось пойти на
хитрость. Работа шла в основном с таблицами, поля связанных таблиц
подтягивались по мере необходимости. Но для ускорения работы те
редко меняющиеся справочники, из которых в основном шло подтягивание
полей, кэшировались на рабочих станциях, естественно, с
отслеживанием актуальности этого кэша.
И, что характерно, сам
перенос занял месяц, и еще два месяца продолжалась борьба за
скорость работы, так как заказчик (странно, не правда ли) требовал,
чтобы новая система работала, по крайней мере, не медленнее, чем
старая…
Еще одна проблема возникает тогда, когда мы
пытаемся предоставить пользователю возможность фильтровать и
сортировать данные по некоторым условиям и выбирать состав полей.
Эта проблема уже в чистом виде относится к средствам разработки
клиентской части программы.
Интерфейсы для задания условий
могут быть разные — от жестко зашитых в экранную форму управляющих
элементов для задания двух-трех типичных ограничений до возможности
накладывать произвольные условия в стиле QBF или табличным набором
ограничений на значения полей. В любом случае нам нужно уметь
сформировать правильный SQL-запрос.
А здесь сразу выясняется,
что этот запрос, кроме условия, наложенного пользователем, должен
содержать еще некоторую предопределенную часть, описывающую не
фильтрованный запрос, и их нужно соединить вместе. Заниматься
синтаксическим анализом имеющегося SQL для того, чтобы вставить в
него новые условия фильтрации и порядок сортировки, очень не
хочется.
Следовательно, нужны структуры данных, где бы
хранились как предопределенные компоненты запроса, так и
определяемые пользователем, и из них нужно уметь строить корректные
SQL-запросы, учитывая множество всяких SQL’ных мелочей: вид кавычек,
требуемый сервером формат представления дат, синтаксис outer join и
др.
К пониманию необходимости динамического порождения
SQL-запросов рано или поздно приходят все разработчики, кроме
разработчиков базового инструментария. Видимо, им самим не
приходится пользоваться своими
творениями.
Многопользовательская работа
Вообще
говоря, многопользовательские приложения — это частный случай
многозадачности. А многозадачность, как известно, влечет одну
фундаментальную проблему: многозадачные приложения практически
невозможно отлаживать, поскольку смоделировать все многообразие
вариантов взаимодействий асинхронно работающих процессов крайне
сложно.
Это сильно поднимает требования к программе. Она
должна быть правильно спроектирована и написана практически без
ошибок. Выясняется также, что многие достаточно хорошие программисты
не в состоянии быстро освоить «параллельный» способ мышления,
необходимый для разработки подобных приложений.
Специфика
многопользовательской работы с данными заключается в том, что в
качестве механизмов управления межзадачным взаимодействием выступают
средства СУБД, то есть транзакции и блокировки, что не снижает
значимости предыдущего замечания. Я не буду описывать принципы,
которыми руководствуются разные серверы баз данных в своей работе,
это предмет обширной специальной литературы. Но некоторые общие
соображения и типичные примеры, мне кажется, будут
полезны.
Все проблемы многопользовательской работы возникают
оттого, что многочисленные и недисциплинированные пользователи могут
одновременно попытаться изменить одни и те же данные. Под
одновременностью понимается не физически одновременная попытка
записать данные, а ситуация, когда один пользователь изменил данные
за то время, пока другой взял их для редактирования, но не успел
сохранить (закончить транзакцию).
В некоторых случаях такие
коллизии очень редки: вероятность, что двое одновременно начнут
редактировать карточку с информацией о контрагенте, ничтожно мала. В
других случаях вероятность коллизии достаточно велика — любая
транзакция купли-продажи меняет остаток на счете
компании.
Существуют две базовые стратегии
многопользовательской работы — пессимистическая и оптимистическая.
Первая предполагает, что все данные, взятые для изменения,
блокируются от изменения другими пользователями, меняются и
отпускаются.
Оптимистическая стратегия исходит из того, что
мы пытаемся выполнить операцию и уже в момент закрытия транзакции
узнаем, что кто-то поменял наши данные до нас. После чего повторяем
попытку.
Разные системы с разными серверами ведут себя
по-разному, и полезно знать, как именно. Когда вы начинаете
редактировать запись базы данных на экране, блокируется ли эта
запись? Если да, не помешает ли это другим, а если нет, что
произойдет с вашими изменениями, когда попытка сохранить запись не
удастся? Сможет ли оператор или ваша программа корректно повторить
попытку?
Если учесть, например, что в MS SQL до версии 6
включительно блокируется не запись, а страница, то есть некоторая
совокупность записей, которым выпало оказаться рядом с
редактируемой, и то, что при неудачной последовательности блокировок
легко организовать клинч, то станет ясно, что политику блокировок
нужно продумывать очень тщательно и редко когда в серьезном
приложении удается обойтись без некоторой своей надстройки над
штатной системой блокировок.
И уж во всяком случае
категорически нельзя допускать, чтобы в последовательность действий,
требующую блокировки, вклинивалось ожидание действий пользователя. Я
наблюдал, как громадная контора в течение часа ждала сотрудника,
который ушел на обед, не закончив редактирование записи (кабинет был
заперт, и сетевой администратор также
обедал).
Оптимистическая стратегия также имеет особенности:
их надо принимать во внимание при проектировании логики программы.
Она должна быть организована так, чтобы все содержательные операции,
которые могут окончиться неудачей из-за вмешательства других
пользователей, были выделены и параметризированы так, чтобы операцию
можно было пытаться повторять «до победного конца», по возможности,
без обращения к оператору.
Причем, как правило, это
приходится делать в клиентской части программы, где средства
программирования все-таки более гибкие и более информативен
контекст.
Рассмотрим тот же складской пример. В нем единой
логической операцией нужно делать исполнение складской проводки с
заданными параметрами. Эта операция должна пытаться выполнить
проводку независимо от значения остатка и оканчивается неудачей в
случае, если товар на складе кончился. Причем операция эта должна
быть отделена от ввода параметров проводки и первичной проверки
наличия товара (которая, как мы видим, ничего не
гарантирует).
Еще один класс проблем вызывают долгие массовые
операции. Они обычно плохо сосуществуют с текущими короткими
транзакциями и вызывают некоторые технические и логические проблемы,
различные для разных серверов.
На время выполнения массовых
модификаций, как правило, имеет смысл заблокировать те данные, с
которыми они работают. Согласитесь, очень обидно, когда процесс,
занявший два часа, неожиданно отключился за десять минут до его
окончания, потому что кто-то что-то неудачно
отредактировал.
Длинные отчеты, не меняющие данные, но
привязанные к определенному моменту времени, также нужно защищать.
Если мы хотим получить состояние склада на 14:00, а соответствующий
отчет генерируется полчаса, то за это время в систему введут еще
десяток проводок, и мы получим отчет, не соответствующий никакому
моменту времени.
Блокировать данные в таких случаях — слишком
суровая мера. Почти все серверы позволяют задать режим isolation
level, при котором открытая транзакция «не видит» данных, измененных
другими транзакциями. Фактически это означает, что для данной
транзакции создается персональная копия тех данных, с которыми она
имеет дело. Хотя это и прозрачно для пользователя, нагрузку на
сервер создает почти такую же, как и массовая
модификация.
Неприятные технические последствия, к которым
приводят массовые операции, зависят от особенностей
сервера.
Interbase (простите, IB Database), например, при
изменении записи оставляет ее предыдущую копию, которая живет, пока
есть хотя бы одна использующая ее транзакция. Потом эти копии
становятся мусором, который нужно ликвидировать специальной
операцией сжатия. Сжатия эти начинаются периодически по некоторым
правилам, и если были массовые операции, сильно подсаживают
сервер.
У Oracle другая проблема — она для этих целей ведет
отдельную структуру данных — журнал отката, размер которого задается
при настройках. В случае длинной транзакции этот журнал может
переполниться. Поскольку заранее не известно, каким должен быть его
размер, иногда приходится в программе делить длинную транзакцию на
части.
И так далее… К сожалению, внятные описания того,
какую политику следует выбирать при работе с транзакциями и
блокировками, чем можно, а чем нельзя пользоваться, — в природе
встречаются крайне редко и являются предметом профессионального
ноу-хау.
Инструментальность средств разработки
По
уровню базовой функциональности все основные системы разработки
клиент-серверных приложений идут «голова в голову». Поэтому
важнейшей их характеристикой является величина порога, который нужно
преодолеть для реализации функций, выходящих за рамки базовых
возможностей. Есть системы, где «шаг в сторону считается побегом», в
других — всякие не предусмотренные разработчиками вещи делаются
достаточно просто, а главное — просто интегрируются со всем
остальным. Я, к сожалению, не знаю, как это свойство обозвать одним
словом.
Для этой характеристики существен ряд факторов —
открытость всех уровней системы, не слишком большой размер
компонентов (модулей). В тех системах, где есть стандартная
оболочка, позволяющая работать с данными (например MS
Access), и
возможность разрабатывать приложения в рамках оболочки, важно, чтобы
вся функциональность этой оболочки была реализована с помощью
доступных инструментальных компонентов.
Зато для следующей,
также принципиально важной характеристики у меня слово есть. Под
инструментальностью я понимаю меру того, в какой степени возможно
реализованные нестандартные решения компактно оформить для
дальнейшего повторного использования. Это свойство сильно зависит от
особенностей используемого разделения системы на компоненты и
инструментальности языка разработки.
По сочетанию этих
параметров наилучшим из известных мне средств является
Delphi, а
наихудшим — MS Access (до версии 7 включительно).
К
разработкам на базе Visual Basic или С++ эти критерии просто
неприменимы: там базовые возможности настолько низкого уровня, что
порог начинается почти сразу, и преодолевать его приходится за счет
высокой инструментальности С++ как языка программирования,
разрабатывая свои библиотеки… На Бейсике это, говорят, тоже стало
возможно, но что-то слабо верится. Генотип у него плохой —
ламерский.
Заключение
На самом деле набор проблем и
тонких мест характерен для каждого сочетания «среда разработки +
сервер БД». Перечисленные проблемы встречаются почти везде. В
некоторых вариантах имеется еще и свои «тараканы».
Как вы
думаете, кто такой специалист по Oracle? Человек, выучивший эту
среду программирования? Нет! Любой грамотный программист выучит ее в
необходимом объеме за месяц. Специалист по Oracle — это человек,
знающий, как ее правильно настроить под особенности конкретной
задачи. Специалист по MS SQL — это человек, твердо знающий, какими
средствами нельзя пользоваться никогда и как обходиться без
них.
Таким образом, чтобы получить приемлемо работающее
приложение, нужно хорошо знать как инструмент разработки, так и
используемый SQL-сервер, а этому, увы, за 21 день не
научишься.